Development
The test data behind all software and applications
How do all those beautiful apps come about on your smartphone?

Just a heads up, if you buy something through our links, we may get a small share of the sale. It’s one of the ways we keep the lights on here. Click here for more.
Nowadays we can’t imagine a world without computers, smartphones, smart TVs, and any other smart devices. We’re more or less addicted to them and most of us know their computer or smartphone inside and out. But do you ever think of the development of all the software and apps on these devices? How did they come about?
Behind every application, there is a team of developers, QA engineers, and testers that builds and tests it. They can build a great application, but if they don’t test it properly, many bugs may arise. Users don’t like bugs so testers want to avoid that in order to launch a successful app that is going to be bought and installed by many people. But what does this development and testing process look like? A quick overview.
Agile and shift left
The traditional development process, also called ‘waterfall’, is a linear approach. It consists of several development stages and each stage finishes before the next one can begin. In most cases, this means that the software or application is designed and coded completely before it is tested. If a test finds any bugs or issues, the entire process has to start over. This costs a lot of time and therefore another methodology was born: agile.

Picture 1. Waterfall development process
Agile is an iterative approach that emphasizes the rapid delivery of apps in complete functional components: tested and all. In contrast to the waterfall development process, in the agile approach testing happens in all phases or stages of the development process. It’s something called ‘continuous testing’ – more of that later on in this article.

Picture 2. Agile development process
Test data
Back to testing. For a proper test, testers need proper test data: data that is as realistic as possible. They want to test if the application works with real data like customer names, email addresses, company names, phone numbers, etc. Because of this need for realistic test data, many test teams use production data; real customer data. The advantage of this is that when the tests pass, they are sure that the application works with the existing production data. The disadvantages, however, are much more important:
- They can’t use Personally Identifiable Information (PII)
- The size of production data and its copies
Let’s start with the first. All over the world, there is privacy legislation in place that states one can’t use privacy-sensitive data for testing and development purposes. At least not as long as it’s unmasked. And the production data probably consists of personally identifiable information so test teams need to have something in place to mask, anonymize, pseudonymize, or de-identify this data.
The second one: some production databases contain gigabytes if not terabytes of data. The problem is not only the time taken to copy and restore but also the size and cost of the space required for each copy. Imagine that the production database grows with 1 TB over time. If there are 3 full copies, the total size increases by 4 TB. A big waste of money (yes, storage costs money).
Continuous testing
Back to shifting left and continuous testing. To be able to test continuously, testers need continuous test data. They need the right test data in the right place at the right time. This all starts with the first masked database that is deployed which then can act as a source for subsequent copies within the lower environments (QA and DEV). It effectively becomes the “Test Data Master”.
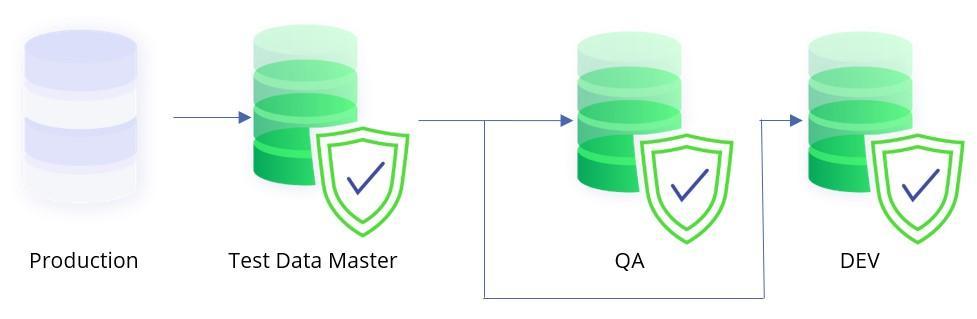
Picture 3. Architecture of masked and copied databases
Creating smaller databases by extracting data from the consistently masked Test Data Master (also called subsetting) means testers are able to execute the same test with exactly the same test data repetitively or even incrementally. Once established, continuous testing improves and accelerates the pace of development. It means that Dev, Test, and QA engineers can focus on executing the right tests on the right data in a timely manner.
Conclusion
If you’ve never heard of the term ‘test data’ before you read this article, you’re probably overwhelmed with all the information – or you didn’t even finish reading it all. But it is good to reflect on what is happening behind the scenes of software/application development. It’s interesting to understand the process of development and testing before you, the user, will download and install a certain application or software. And maybe, with this knowledge in mind, you have a little more respect for the developers when you come across a bug they tried so hard to prevent.
 Editor’s Note: Nynke Hogeveen is a communications adviser at DATPROF, a leading Test Data Management solutions provider. By sharing knowledge and offering the right tools she wants to make Test Data Management more accessible to every organization. The main goal is to simplify getting the right test data in the right place at the right time.
Editor’s Note: Nynke Hogeveen is a communications adviser at DATPROF, a leading Test Data Management solutions provider. By sharing knowledge and offering the right tools she wants to make Test Data Management more accessible to every organization. The main goal is to simplify getting the right test data in the right place at the right time.
Have any thoughts on this? Let us know down below in the comments or carry the discussion over to our Twitter or Facebook.
Editors’ Recommendations:
- 7 vital tips to protect your data online
- How to tell the difference between a secure data room and a shared drive
- Data centers and AI: 3 major challenges in the colocation market
- Web scraping vs. data mining: Understanding the differences
Follow us on Flipboard, Google News, or Apple News