Just a heads up, if you buy something through our links, we may get a small share of the sale. It’s one of the ways we keep the lights on here. Click here for more.
Microsoft has created a new AI that can create a deepfake of a person’s voice from a three-second audio sample.
Called VALL-E, it can recreate anyone’s voice from a short snippet of recorded speech. That’s insane enough on its own, but the AI model doesn’t stop there.
The Microsoft researchers detailed the process in a paper, and the results are impressive. VALL-E can also recreate emotional tone and match the timbre of the speaker.
Think of the possibilities. Automated phone assistants that actually sound like a real person and the ability to recreate voices of the dead, provided there is a recording of them when they were alive.
The other side of the coin is that this tool could be easily misused. Other AI generators have been used to deepfake porn, audio, and famous people.
VALL-E is the newest deepfake tool
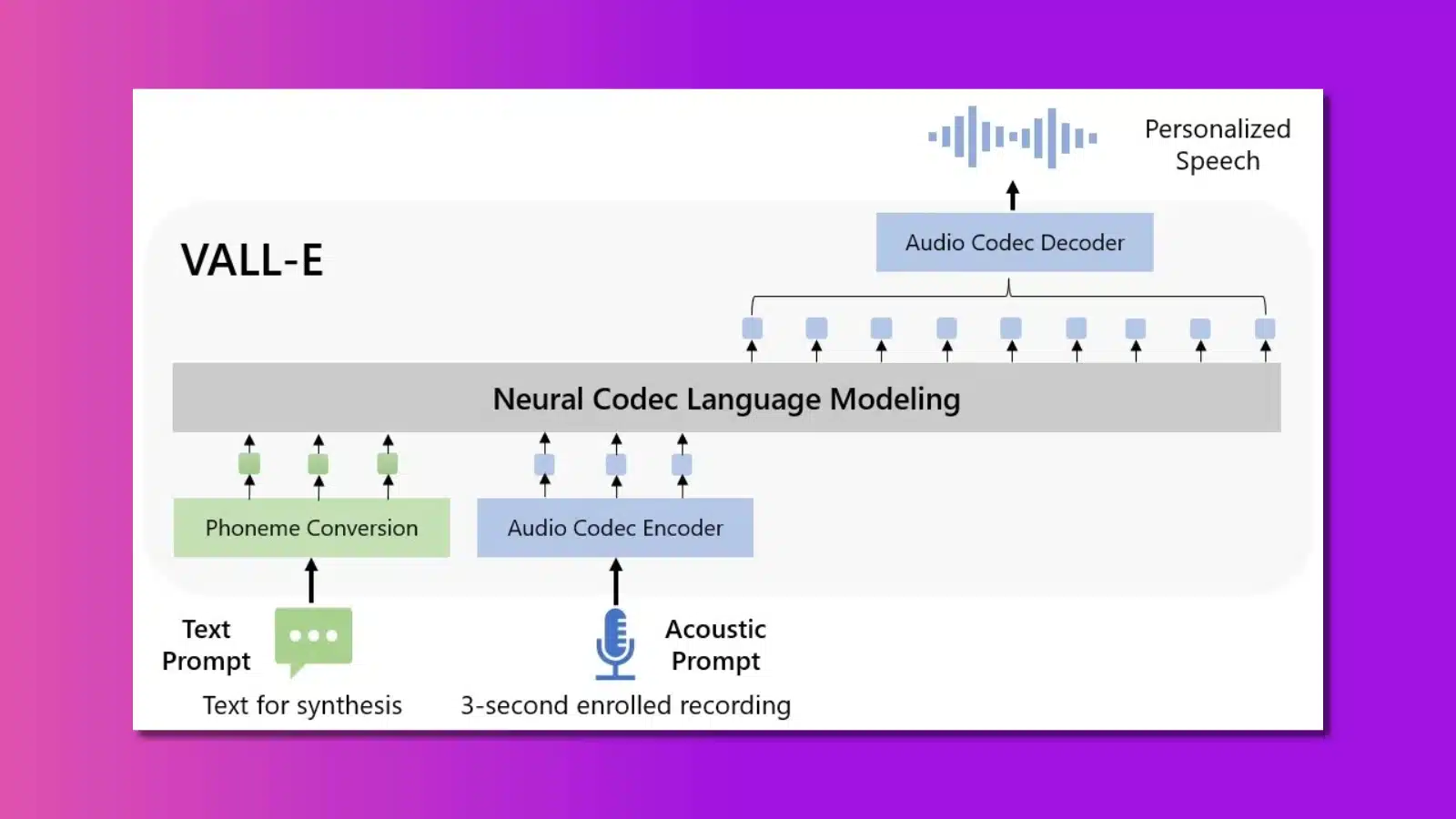
The researchers trained the AI model on 60,000 hours of English language speech. The dataset came from Meta’s LibriLight audio library, which uses public domain audiobooks from LibriVox as the source.
That’s important, as the training data is copyright-free and, therefore, ethical to use. Some of the other AI tools, like DALL-E, used data scraped from the internet, with varying levels of ethical ramifications.
The good news for those worried about deepfakes is that VALL-E has varying levels of success. The output can be machine-like at times, but at other times it is convincingly similar to the original speaker.
Microsoft is far from finished with this AI model. The company plans to continue training it by feeding more data to analyze.
That will mean ever more accurate representations of the recorded speaker.
It’s good that Microsoft is keeping the model closed-source for now. That limits the potential for misuse.
In other related news, Microsoft is in talks with ChatGPT creator OpenAI, with the view of investing $10 billion in the company. That’s ten times the existing investment, which Microsoft made in 2019.
Have any thoughts on this? Carry the discussion over to our Twitter or Facebook.
Editors’ Recommendations:
- Microsoft is infusing Bing search with ChatGPT
- Student creates tool that exposes AI-generated text
- New Nvidia AI tech unblurs grainy YouTube videos
- Google Home speakers were at risk of eavesdropping hackers
Follow us on Flipboard, Google News, or Apple News